The Big Data revolution transcends the technological scene. Be immersed in a ocean of data also means to be able to daily generate information from different sources and activities.
An environment where privacy is gaining importance due to the constant violations or uses that even though are considered legal, they are no always seen as ethical. In addition, challenges for data protection are getting harder to achieve.
Artificial intelligence is a concept that includes automatic or machine learning, so a first approximation to both terms places us already in a context of subordination that in no way implies inferiority. [Read more…]
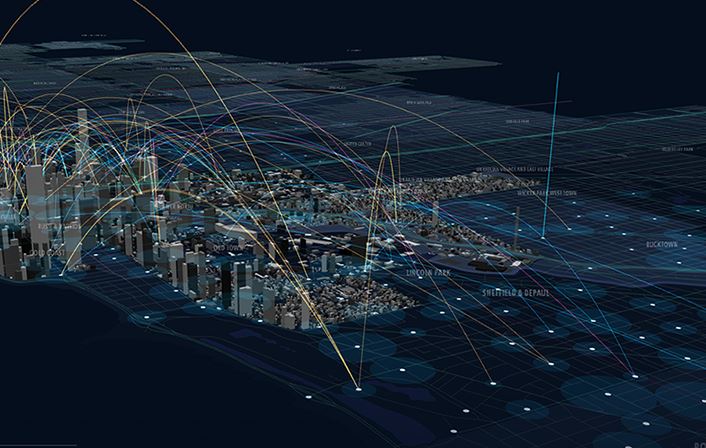
Geolocation applications and those that, without being specific, include the spatial dimension, are becoming more numerous. Not in vain, even though they are heterogeneous, many of the data generated by Big Data and the Internet of Things –IoT– are characterized by the fact that they have a geographical component.
Since the emergence of the first forms of writing until now, people have had the need to collect information; information that, logically, has been accumulated along years, becoming more abundant and profuse over time. Today, the growth of the technology sector has also caused a disproportionate increase in the volume of information data.
Visualization is one of the most primitive forms of communication known by people. That is why vision is the single main faculty that a person uses to communicate and share information.
The greatest challenge of Big Data revolution poses many issues that are easier to deal with due to the development of industries related to information technology and communications. Today we will present the differences between IoT and M2M.
The terms Big Data and Data Science are associated with large volumes of data characterizing the new technological era. In particular, with the collection, analysis and, as an ultimate objective, extraction value of such data to aid in decision making.
New times are marked by the sign of the digital age, globalization and the huge amount of mass data generated daily. Big Data is rigged to great challenges and better opportunities.
Beyond the famous5 Vs that characterize it (volume, velocity, variety, veracity and value), Big Data have great possibilities in the most unimaginable fields. And it does, especially, because new technologies have emerged to respond, with unprecedented efficiency, to the needs of storage and analysis of big data.
There are many technologies and concepts that are part of this universe of big data, whose growth is unstoppable, as the Internet of Things (IoT), data exchange machine to machine (M2M), the increasingly complex environment of IT or predictive machine learning.
The importance of process data
The Big Data challenges, in effect, require capable approaches and systems to collect, store, make efficient searches and, finally, carry out analysis, whose results could be conveniently displayed.
But these challenges are accompanied by a whole world of opportunities for many different actors, in a scientific or enterprise level, or with regard to public organizations.
The knowledge revolution has arrived and the goal is clear: valuing data to exploit them, a key point in which, in addition to innovative technologies, come into play data science and data scientist´s figure.
It is, in short, the way to apply technologies, creating ad hoc strategies and methodologies to implement complex algorithms that provide us an insider view to better decision-making.
Not surprisingly, the data serve less if we do not implement custom solutions. Without a purpose and a technology capable to manage it, the data value will be zero. In contrast, processing that information in the desired direction provides a good data management to obtain comparative advantages.
The same finding of the information sought is, in itself, a great success, the key that will allow us to advance in our goal. Therefore, the data is not an end in them, but it is the best way to reach this really valuable information, that will make the difference.
The goals could be very different types, from monetizing the information to make it an effective tool to improve governance, as occurs in smart cities projects.
Within this complex but exciting context, the fashionable part of artificial intelligence dedicated to learning by machines,machine learning is based on systems that automatically learn.
We understand that action learning as identifying complex patterns in millions of data. Basically, the machine is able to predict behaviour “learning” an algorithm that checks the data.
The peculiarity of these methods of prediction, based on algorithmic methods where the certainty of the theoretical model makes way for approximate models based on Probability and Statistics. This way of modelling reality, based on probabilities, is that our brain follows, supported by its large capacity computing. The absolute certainty does not exist for our brain; each of us interprets reality and adjusted it according to a certain probability, required at the time.
Free absolute certainty model, as previously described, its confidence level will move within a given fork, considered a significant level of efficiency. To this end, it will be decisive the practical utility that could provide a certain percentage of correct answers.
And the results could be spectacular, as demonstrated by two of his greatest achievements: theGoogle voice recognition orfacial Facebook. In both cases, without reaching the actual model, which underlies each one, applying machine learning algorithms and obtaining approximate models with an acceptable margin of error and with a huge computing speed. It is this computation speed what we pursue in most cases, looking for a very small error in prediction in a time acceptable to the application.
Machine learning applications
Fields of application of machine learning are endless. Sectors such as e-commerce and marketing, in general, are just a tiny sample of how much a project of machine learning can offer.
When planning any initiative, imagination can play a big role, no restrictions other than the legality and ethics. The scope, in short, depends on the margin, budget and data are available.
Data science teams have in machine learning a great ally. While there are hybrid approaches, they are self learning systems within an ocean of data, without further programming.
Machine learning, for example, is the heart of the recommendations systems of giants network, likeeBay,Amazon,Twitter,Facebook orLinkedIn, as well as a host of projects fraud detection networks, data communications, recognition voice, breakdowns in machinery, technological equipment failures, algorithms for predicting disease, leads, crimes or consumer trends.
Machine learning applications in Smart City
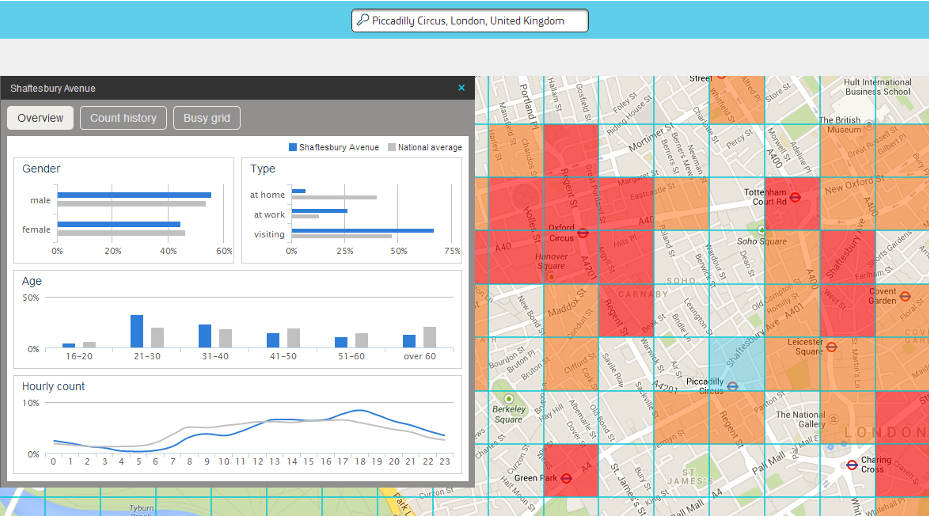
At the level of the smart city, any progress in this area could have very interesting applications. From the facial or voice recognition to carry out programs of social inclusion of disabled people to, say, flexible behaviour of a mobile application to suit the preferences and needs of each user.
Predicting the urban traffic or make medical pre-diagnosis based on the patient’s symptoms are other examples of projects under the environment of the smart city that could arise, exploiting the great potential of anonymous data.
Far from being useless, they can actually contribute much value, as demonstrated in the following three next examples, focused on improving public health, sustainable mobility and safety in cities.
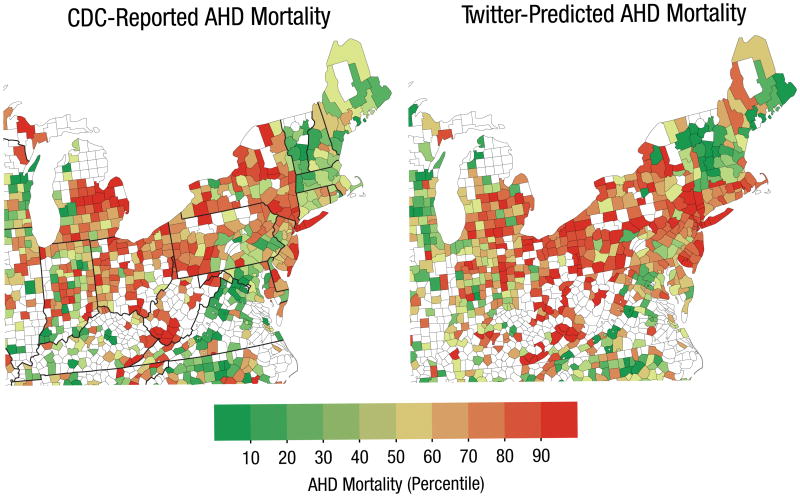
First, American psychologists found useful information to improve preventive health policies. This time, they succeeded analyzing the optimistic or pessimistic tone of the tweets in different geographical areas and establishing a correlation with death rates for heart problems.
By overlaying a map generated by the tweets on the map pointing mortality data for coronary pathologies, they found striking similarities. By analyzing 148 million tweets from 1347 US counties, predicting rates of heart disease more effectively than traditional risk factors, including obesity, diabetes or smoking.
The conclusion of thestudy, conducted by scientists at the University of Pennsylvania, offers no doubt: the social and spatial environment has a decisive influence on coronary problems. Ultimately, an effective social level analysis can not apply to private individuals, but it is of great importance to implement ad hoc policies. And even to track the results, once implemented campaigns.
In the design of smart cities, on the other hand, sustainable mobility is one of the major objectives. In this regard, the IEEE International Workshop on Urban Mobility and Intelligent Transportation Systems UMITS 2016 was a landmark event in which leading initiatives for urban mobility and intelligent transportation systems were presented.
One of the strengths of the project, precisely, lies in the development of different traffic variables prediction algorithms (intensity of vehicles on a road or occupancy), fed by data in real time from the city of Madrid.
According to its creators, it was by applying machine learning techniques, with the objective to study different issues, affecting the traffic, as it was possible to improve the effectiveness of predictions.
Finally, a joint effort of Fondazione Bruno Kessler (FBK), MIT and Telefónica R&D is one of the main achievements of machine learning to anticipate social risks from the analysis of human behaviour.
In this case, related to crime. Its project,“Crime Hot Spots” is a minefield of data generated by smartphones, which could detect future crime scenes. Specifically, it could predict in which district is more likely that a crime occurs in the city of London, with an accuracy of about 70 percent.
Compared to conventional systems, it represents a huge step forward. Instead of relying on costly and time consuming data collection of crime statistics and local demographics, it uses a log made from criminals and demographic statistics City sources, along with data emitted by mobile phones to collect key information about its owners, as its geolocation in real time, as well as sex and age.
After a phase of refining the system to ensure the anonymity of the data and after adapting to other cultural environments, it is important to provide information for public use. Its creators are not doing anything wrong when they claim that their results could be of great interest to governments and security forces.
Why do we make tiles? For a reason of efficiency and speed. To create tiles consists of making a pyramid of the world and rendering the images previously. In this way our maps are faster because they only download the images that had been rendered.
The WMS services were good several years ago but today the needs are a quite different, and there are much better solutions for applications dealing with a large quantity of users. It has it’s uses, but it’s not a solution for scalable applications.
I’d like to tell you our experience:
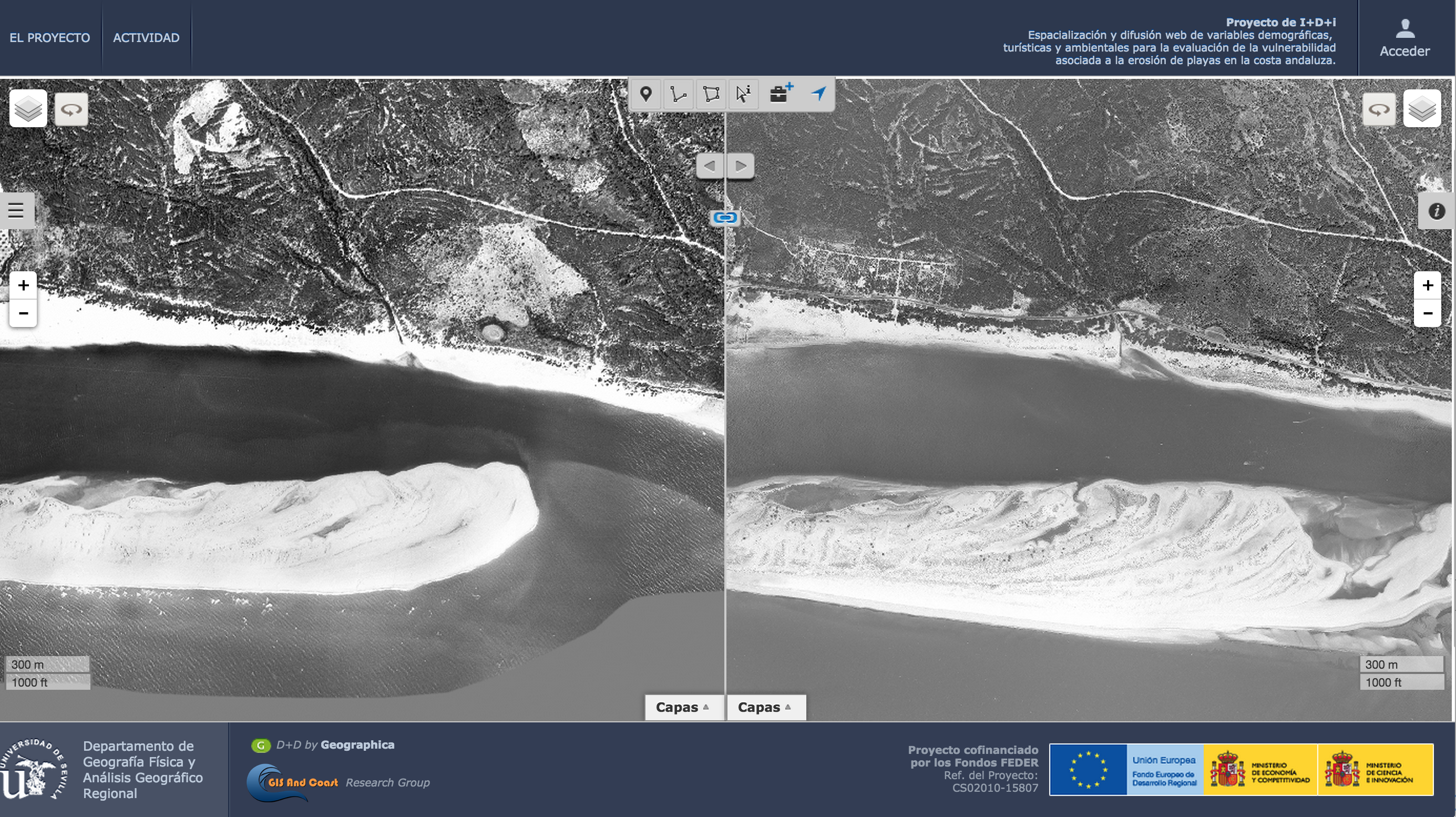
We tile the orthophoto of Andalusia with an high level of detail (level 18). For that we used gdal2tiles.py. The first issue to deal with was the format, for the year 1956 it was a MrSID and we had to fight a bit with GDAL. The second one, and much harder, was to create the mosaic.
El rompido, year 1956 on the left and the year 1979 on the right
Even thought we achieved it, it looked really well but it took too much time (50 days). It was unacceptable so we start working to improve the timing and furthermore to have something that allow us to take data from the most common data sources.
The target was to tile the maps of each of our applications without thinking about the format of the data. We create Equidna – 100% OpenSource -, with this tools we’ve created hundreds of maps for different clients and we’ve been able to reduce the timing thanks to a multiprocessing implementation. It was a large improvement, using gdal2tiles it took 50 days and with Equidna we reduced it to 30 days.
Equidna is based on Mapnik and it allows you to make tiles with a wide variety of data sources: PostGIS, Shapefiles, GeoJSONs, GDAL, raster, etc…
Right now, we’re working on an improvement based on BigData using a Map/Reduce algorithm (despite of I’m not a fan the term “BigData” I think it helps for a better understanding). With this new approach we assign each machine a region of the world.
So, using an elastic platform as Amazon EC2 we can launch N machines; if a process takes 50 days, if we launch 50 machines it will take 1 day (aprox.) and the cost will be the same. We’re developing this platform on Spark.
In a few months we’ll post the results, and of course, it will be OpenSource.